


The Meta Movie Gen collection provides a set of foundational models that give creators the tools to create, customize, and edit hyper-realistic videos with audio through text descriptions. In this way, Zuckerberg joins other companies in creating artificial intelligence (AI) tools to create videos, as OpenAI did with Sora last February.
This new tool, In meta wordsAimed at content creators and filmmakers, it aims to help “enhance rather than replace their creativity”. Movie Gen has two functional models, one targeting video (Movie Gen Video) with 30,000 million parameters and the other focused on generating sounds (Movie Gen Audio) with 13,000 million parameters.
Zuckerberg put it to the test
As Meta explains, the way Movie Gen works is similar to other utilities of this type. It is possible to create a video between 4 and 16 seconds long at 16 frames per second with just a text description. AI also lets you edit existing clips using different text descriptions or create personalized videos by uploading a user’s photo. Although the company says the material is hyper-realistic and of full HD quality, Meta chose to make them at 16 FPS rather than 24 frames per second style as is done in the film industry.
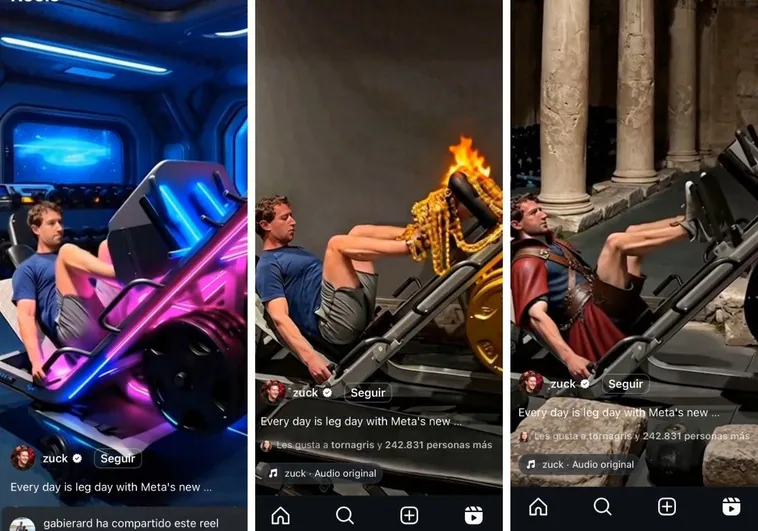
Zuckerberg himself gave a first look at Meta Movie Gen’s capabilities via a post on Instagram. In it you can see him exercising while different objects in the background, his clothes or equipment change according to what is asked of the artificial intelligence.
Ability to generate audio
One of the main differentiating aspects of Movie Gen is its ability to generate sounds for the videos in question. Note that tools like Sora, for example, do not offer this possibility. According to its creators, the 13 billion parameter model can use video and text description to create an audio track that matches what’s happening in the image.
In the examples shared by Meta, a quad can be seen accelerating and jumping, with the sound of an engine playing in the background along with the music. You can see a snake moving among the vegetation, accompanied by the sound of leaves and AI-generated music. In this case, the audio allows a maximum duration of 45 seconds and can achieve everything from ambient sounds to instrumental music. However, it does not allow the creation of voices or dialogue, presumably to avoid the production of deepfakes.



{kind=link}